您现在的位置是:主页 > news > 温州seo关键词优化/seo排名计费系统
温州seo关键词优化/seo排名计费系统
![]() admin2025/4/27 4:14:10【news】
admin2025/4/27 4:14:10【news】
简介温州seo关键词优化,seo排名计费系统,手机网站跳出率低,06年可以做相册视频的网站实验目的 任意选择分类算法,实现乳腺癌分类。要求所有分类算法均自己实现。 下图是一个良性样本: 下图是一个恶性样本: 实验过程 由于能力和精力有限,我并没有选用CNN模型作为分类器。一方面是因为不借助PyTorch框架实现CNN对…
实验目的
任意选择分类算法,实现乳腺癌分类。要求所有分类算法均自己实现。
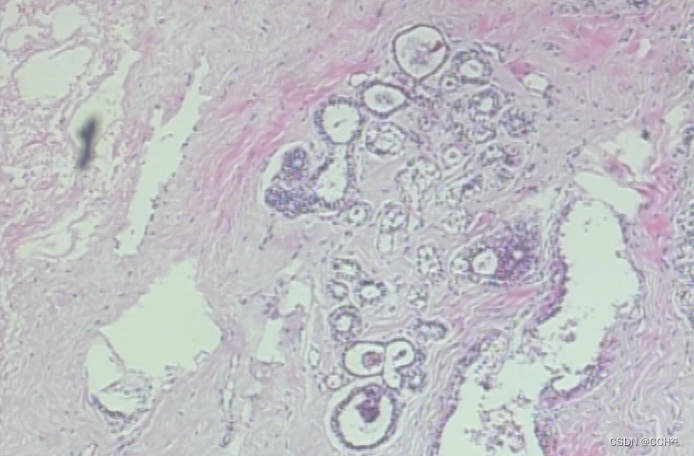
下图是一个良性样本:
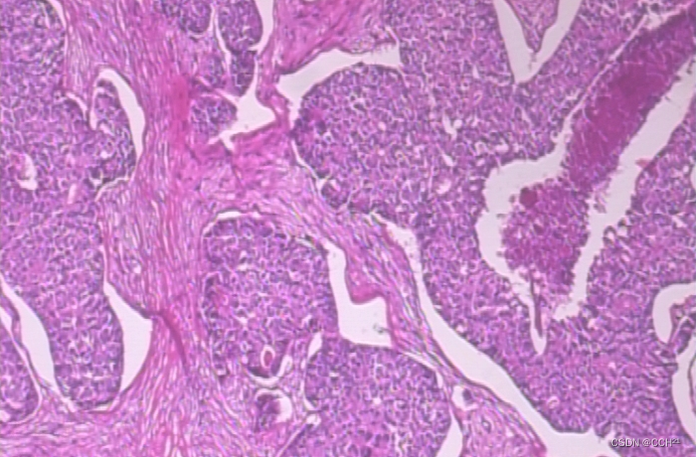
下图是一个恶性样本:
实验过程
由于能力和精力有限,我并没有选用CNN模型作为分类器。一方面是因为不借助PyTorch框架实现CNN对我来说过于困难,另一方面是因为本次课内实验提供的数据量太小,我觉得没有必要通过卷积神经网络来进行分类,故本次实验选用了相对简单的全连接神经网络实现。
①数据集的读取
本次实验的数据集正类样本和负类样本存放于两个不同的目录,因此可以调用Python的os模块,列举出目录中的所有文件并进行读取,作为数据集的特征。经过观察各图片的命名,可以发现所有的正类样本命名均为SOB_B_...,负类样本命名均为SOB_M_...,故可以从文件名入手,以下划线作为分隔符对文件名运用split方法,通过索引为1的元素(B或M)来确定数据样本的标签。每读取一个样本,就将其加入dataset列表,便于后续划分训练集和验证集。
def read_data(self):dataset = []for dir_name in self.dir_names:for filename in os.listdir(r'./data/' + dir_name):img = cv2.imread(r'./data/' + dir_name + '/' + filename)label = 0 if filename.split('_')[1] == 'B' else 1dataset.append([img, label])return dataset
②数据集的划分
根据设定的test_size参数来划分出训练集和验证集。划分前通过random.shuffle方法对数据集洗牌,确定训练集和测试集大小后通过切片的方式进行划分,进一步提取出对应的特征和标签。对于数据样本的特征,输入网络时可将图像三个通道的像素展平,但这样可能会丢失一些上下相邻像素点之间的关联。
def train_test_split(self, dataset):random.shuffle(dataset)data_len = len(dataset)test_len = int(data_len * self.test_size)train_len = data_len - test_lentrain, test = dataset[:train_len], dataset[train_len:]X_train = np.array([i[0] for i in train])y_train = np.array([[i[1]] for i in train]).reshape(1, -1)X_test = np.array([i[0] for i in test])y_test = np.array([[i[1]] for i in test]).reshape(1, -1)X_train = X_train.reshape((X_train.shape[0], -1)).TX_test = X_test.reshape((X_test.shape[0], -1)).Treturn X_train, X_test, y_train, y_test
③全连接神经网络
编写my_nn类实现全连接神经网络,从本质上来说是通过训练得到每两层之间的权重和偏置(即W1、b1、W2、b2),训练之前应对其进行随机初始化。神经网络的训练过程可以分为前向传播和反向传播。在前向传播中,设置隐藏层后使用tanh函数激活,输出结果使用sigmoid函数(调用scipy.special.expit实现)映射到 [0,1][0, 1][0,1] 区间。反向传播则是对矩阵求导,通过梯度下降法优化网络参数。
def init_parameters(self):W1 = np.random.randn(self.hidden_layer, self.input_layer) * 0.01b1 = np.zeros((self.hidden_layer, 1))W2 = np.random.randn(self.output_layer, self.hidden_layer) * 0.01b2 = np.zeros((self.output_layer, 1))return W1, W2, b1, b2def tanh(self, x):return 2 / (1 + np.exp(-2 * x)) - 1def forward(self, W1, W2, b1, b2, x):z1 = np.dot(W1, x) + b1a1 = self.tanh(z1)z2 = np.dot(W2, a1) + b2y_hat = expit(z2)return y_hat, a1def backward(self, y_hat, a1, W2, N):dz2 = (-1 / N) * (self.y * (1 - y_hat) - y_hat * (1 - self.y))dW2 = np.dot(dz2, a1.T)db2 = dz2.sum(axis=1, keepdims=True)dz1 = np.dot(W2.T, dz2) * (1 - a1 ** 2)dW1 = np.dot(dz1, self.X.T)db1 = dz1.sum(axis=1, keepdims=True)return {'dW2': dW2, 'db2': db2, 'dW1': dW1, 'db1': db1}def optim_GD(self, W1, W2, b1, b2, lr, grids):W1 -= lr * grids['dW1']W2 -= lr * grids['dW2']b1 -= lr * grids['db1']b2 -= lr * grids['db2']return W1, W2, b1, b2
本次实验的神经网络设置隐藏层神经元数量为16,训练迭代次数为2000,学习率为0.1,损失函数选择交叉熵损失函数。
完整代码实现
项目结构如下图所示:

my_nn.py
import os
import randomimport cv2
import numpy as np
from scipy.special import expitclass my_nn:def __init__(self, X, y, hidden_layer, iters, lr):self.X = Xself.y = yself.input_layer = self.X.shape[0]self.output_layer = self.y.shape[0]self.hidden_layer = hidden_layerself.iters = itersself.lr = lrdef init_parameters(self):W1 = np.random.randn(self.hidden_layer, self.input_layer) * 0.01b1 = np.zeros((self.hidden_layer, 1))W2 = np.random.randn(self.output_layer, self.hidden_layer) * 0.01b2 = np.zeros((self.output_layer, 1))return W1, W2, b1, b2def tanh(self, x):return 2 / (1 + np.exp(-2 * x)) - 1def forward(self, W1, W2, b1, b2, x):z1 = np.dot(W1, x) + b1a1 = self.tanh(z1)z2 = np.dot(W2, a1) + b2y_hat = expit(z2)return y_hat, a1def backward(self, y_hat, a1, W2, N):dz2 = (-1 / N) * (self.y * (1 - y_hat) - y_hat * (1 - self.y))dW2 = np.dot(dz2, a1.T)db2 = dz2.sum(axis=1, keepdims=True)dz1 = np.dot(W2.T, dz2) * (1 - a1 ** 2)dW1 = np.dot(dz1, self.X.T)db1 = dz1.sum(axis=1, keepdims=True)return {'dW2': dW2, 'db2': db2, 'dW1': dW1, 'db1': db1}def optim_GD(self, W1, W2, b1, b2, lr, grids):W1 -= lr * grids['dW1']W2 -= lr * grids['dW2']b1 -= lr * grids['db1']b2 -= lr * grids['db2']return W1, W2, b1, b2def cross_entropy(self, y_hat, N):assert self.y.shape == y_hat.shapereturn (-1 / N) * (np.dot(self.y, np.log(y_hat.T)) + np.dot((1 - self.y), np.log((1 - y_hat).T)))def cal_acc(self, y, y_hat):y_hat = y_hat.Tfor i in range(len(y_hat)):y_hat[i] = 0 if y_hat[i] < 0.5 else 1acc = (np.dot(y, y_hat) + np.dot(1 - y, 1 - y_hat)) / float(len(y_hat))return acc, y_hatdef fit(self):W1, W2, b1, b2 = self.init_parameters()print('-' * 40 + ' Train ' + '-' * 40)for i in range(1, self.iters + 1):y_hat, a1 = self.forward(W1, W2, b1, b2, self.X)if i % 50 == 0:cost = self.cross_entropy(y_hat, self.X.shape[1])[0][0]acc, _ = self.cal_acc(self.y, y_hat)acc = acc[0][0]print('[Train] Iter: {:<4d} | Loss: {:<6.4f} | Accuracy: {:<6.4f}'.format(i, cost, acc))grids = self.backward(y_hat, a1, W2, self.X.shape[1])W1, W2, b1, b2 = self.optim_GD(W1, W2, b1, b2, self.lr, grids)return {'W1': W1, 'W2': W2, 'b1': b1, 'b2': b2}def eval(self, X_test, y_test, parameters):W1 = parameters['W1']W2 = parameters['W2']b1 = parameters['b1']b2 = parameters['b2']y_pred, _ = self.forward(W1, W2, b1, b2, X_test)acc, y_pred = self.cal_acc(y_test, y_pred)acc = acc[0][0]print('-' * 40 + ' Eval ' + '-' * 40)print('[Eval] Accuracy: {:<6.4f}'.format(acc))return y_predclass Dataset:def __init__(self, dir_names, test_size):self.dir_names = dir_namesself.test_size = test_sizedef read_data(self):dataset = []for dir_name in self.dir_names:for filename in os.listdir(r'./data/' + dir_name):img = cv2.imread(r'./data/' + dir_name + '/' + filename)label = 0 if filename.split('_')[1] == 'B' else 1dataset.append([img, label])return datasetdef train_test_split(self, dataset):random.shuffle(dataset)data_len = len(dataset)test_len = int(data_len * self.test_size)train_len = data_len - test_lentrain, test = dataset[:train_len], dataset[train_len:]X_train = np.array([i[0] for i in train])y_train = np.array([[i[1]] for i in train]).reshape(1, -1)X_test = np.array([i[0] for i in test])y_test = np.array([[i[1]] for i in test]).reshape(1, -1)X_train = X_train.reshape((X_train.shape[0], -1)).TX_test = X_test.reshape((X_test.shape[0], -1)).Treturn X_train, X_test, y_train, y_testmain.py
from my_nn import Dataset, my_nndir_names = ['benign', 'malignant']
dataset = Dataset(dir_names, 0.3)
X_train, X_test, y_train, y_test = dataset.train_test_split(dataset.read_data())model = my_nn(X_train, y_train, 16, 2000, 0.1)
parameters = model.fit()
model.eval(X_test, y_test, parameters)实验结果如下图所示:
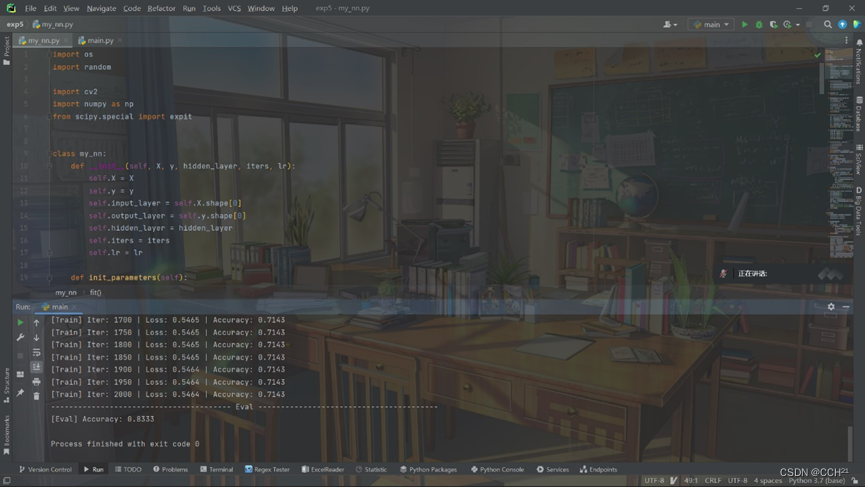
由于只是一次课内实验,数据样本过少(正、负类样本各10张),很难通过分类的准确率来评判这个模型,但训练过程中损失值是在不断下降的。








