您现在的位置是:主页 > news > 就是做网站的...../seo外包公司优化
就是做网站的...../seo外包公司优化
![]() admin2025/4/21 15:28:34【news】
admin2025/4/21 15:28:34【news】
简介就是做网站的.....,seo外包公司优化,如何搭建一个完整的网站,外贸设计网站Crawler:爬虫基于urllib.request库实现获取指定网址上的所有图片目录输出结果核心代码输出结果核心代码# codinggbk import urllib.request import re import os import urllibdef getHtml(url): #指定网址获取函数page urllib.request.urlopen(url)html page.…
就是做网站的.....,seo外包公司优化,如何搭建一个完整的网站,外贸设计网站Crawler:爬虫基于urllib.request库实现获取指定网址上的所有图片目录输出结果核心代码输出结果核心代码# codinggbk
import urllib.request
import re
import os
import urllibdef getHtml(url): #指定网址获取函数page urllib.request.urlopen(url)html page.…
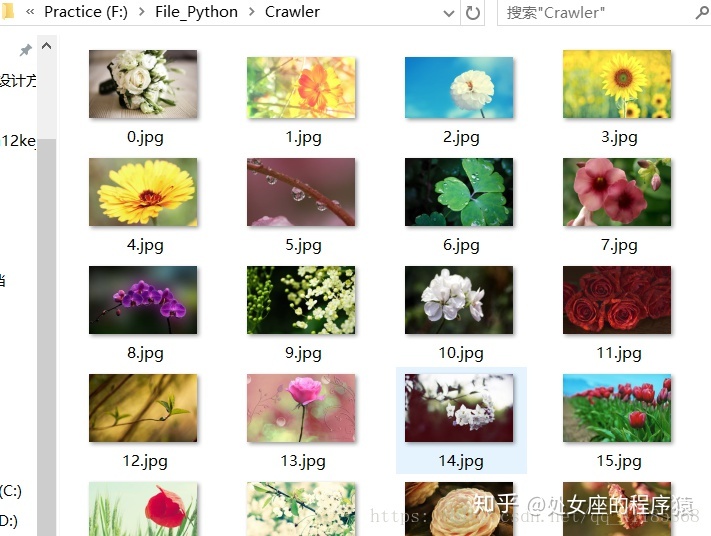

Crawler:爬虫基于urllib.request库实现获取指定网址上的所有图片
目录
输出结果
核心代码
输出结果
核心代码
# coding=gbk
import urllib.request
import re
import os
import urllibdef getHtml(url): #指定网址获取函数page = urllib.request.urlopen(url)html = page.read()return html.decode('UTF-8')def getImg(html): #定义获取图片函数reg = r'src="(.+?.jpg)" pic_ext'imgre = re.compile(reg)imglist = imgre.findall(html)x = 0path = r'F:File_PythonCrawler' # 将图片保存到F:File_PythonCrawler文件夹中,如果没有Crawler文件夹,将会自动则创建if not os.path.isdir(path): os.makedirs(path) paths = path+'' for imgurl in imglist: #打开in集合中保存的imgurl图片网址,循环下载图片保存在本地urllib.request.urlretrieve(imgurl,'{}{}.jpg'.format(paths,x)) x = x + 1 return imglist
html = getHtml("https://tieba.baidu.com/p/2460150866?pn=10")#指定获取图片的网址路径
print (getImg(html))








