您现在的位置是:主页 > news > sns网站设计/如何宣传网站
sns网站设计/如何宣传网站
![]() admin2025/4/29 23:45:39【news】
admin2025/4/29 23:45:39【news】
简介sns网站设计,如何宣传网站,wordpress网站发布文章,qq炫舞做字网站01、内建名称空间 在Python中,有一个内建模块,该模块中有一些常用函数,变量和类。 而该内建模块在Python启动后、且没有执行程序员所写的任何代码前,Python首先会自动加载该内建模块到内存。 另外,该内建模块中的功…
01、内建名称空间
在Python中,有一个内建模块,该模块中有一些常用函数,变量和类。
而该内建模块在Python启动后、且没有执行程序员所写的任何代码前,Python首先会自动加载该内建模块到内存。
另外,该内建模块中的功能可以直接使用,不用在其前添加内建模块前缀,其原因是对函数、变量、类等标识符的查找是按LEGB法 则,其中B即代表内建模块。
__builtin__和builtins的区别
在Python2.X版本中,内建模块被命名为__builtin__,而到了Python3.X版本中,却更名为builtins,二者指的都是同一个东西,只是名字不同而已。
当使用内建模块中函数,变量和类等功能时,可以直接使用,不用添加内建模块的名字,也不用手动导入内建模块。但是,如果想要向内建模块修改或者添加一些功能,以便在程序其他地方使用时, 这时需要手动import。
builtins就是内建模块的一个引用
虽然是一个引用,但builtins和内建模块是有一点区别的:
要想使用内建模块,都必须手动import内建模块,而对于builtins却不用导入,它在任何模块都直接可见, 有些情况下可以把它当作内建模块直接使用。
builtins虽是对内建模块的引用,但这个引用要看是使用builtins的模块是哪个模块:
在主模块main中:
builtins是对内建模块builtin本身的引用,即builtins完全等价于builtin,二者完全是一个东西,不分彼此。
在非main模块中:
builtins仅是对builtin.dict的引用,而非builtin本身。它在任何地方都可见。此时builtins的类型是字典。
在Pycharm中查看bulidins的源码,只能看到空函数的定义?
如果是c 语言实现的模块,则不能直接在IDE里面查看,如果直接在IDE里面查看,会发现没有实现,其实那是IDE自己生成的
比如 builtins.py ,可以看到它的路径是pycharm下的一个文件
python的内置函数都是内嵌在解释器里面的,是使用C编写的,正常情况下你是无法查看的,只不过pycharm这种智能编辑器对其进行了一个抽象罢了,可以让你查看相应的注释。
事实上不仅是内置函数,还有pyd这种二进制文件,你也是无法直接查看它的源代码的,pycharm同样将pyd文件也抽象成一个普通的py文件,可以让你直接点击进去查看都定义哪些函数和哪些类,以及相应的注释等等。
但是代码的具体实现不是通过python编写的,你在使用内置函数的时候实际上是解释器内部使用C编写的函数,调用pyd文件的时候也是调用pyd文件里面的函数和类。只不过这些你无法直接查看,所以pycharm才把它们抽象成普通的py文件,事实上你把这些py文件都删除,也不影响使用。只不过没有了这些文件,也就无法使用pycharm的编辑提示、自动补全等功能了。
所以python内置函数只有一个pass,是因为你看的是pycharm抽象出来的py文件,为了让你看到这些你无法直接查看的文件里面都定义了哪些函数、哪些类、哪些变量,以及相应的注释,为了你方便学习的,执行代码的时候和这些文件没有任何关系。而上面也说了,既然代码块的内容不是python实现的,所以直接写上了一个pass。

比如内置函数len,它是C编写的,编译之后就内嵌在解释器里面了。pycharm通过def len()的方式告诉你这是一个函数,名字叫做len,根据注释提示你:这是返回一个容器内部元素的个数。函数体只有一个pass,是因为代码的具体实现是通过C实现的,该文件只是起到一个让你学习的辅助作用。
02、命名空间与作用域
名称空间即存放名字与对象映射/绑定关系的地方。对于x=3,Python会申请内存空间存放对象3,然后将名字 x 与 3 的绑定关系存放于名称空间中,del x表示清除该绑定关系。
在程序执行期间最多会存在三种名称空间:内置名称空间、全局名称空间、局部命名空间
♥ 内置名称空间
存放的名字 : 存放的python解释器内置的名字’
存活周期 : python解释器启动则产生,python解释器关闭则销毁
♥ 全局名称空间
存放的名字 : 只要不是函数内定义、也不是内置的,剩下的都是全局名称空间的名字存活
存活周期 : python文件执行则产生,python文件运行完毕后销毁
♥ 局部名称空间
存放的名字 : 在调用函数时,运行函数体代码过程中产生的函数内的名字
存活周期 : 在调用函数时存活,函数调用完毕后则销毁
全局作用域与局部作用域
按照名字作用范围的不同可以将三个名称空间划分为两个区域:
全局作用域 : 位于全局名称空间、内建名称空间中的名字属于全局范围,该范围内的名字全局存活(除非被删除,否则在整个文件执行过程中存活)、全局有效(在任意位置都可以使用);
局部作用域 : 位于局部名称空间中的名字属于局部范围。该范围内的名字临时存活(即在函数调用时临时生成,函数调用结束后就释放)、局部有效(只能在函数内使用)。
在局部作用域查找名字时,起始位置是局部作用域,所以先查找局部名称空间,没有找到,再去全局作用域查找:先查找全局名称空间,没有找到,再查找内置名称空间,最后都没有找到就会抛出异常
在全局作用域查找名字时,起始位置便是全局作用域,所以先查找全局名称空间,没有找到,再查找内置名称空间,最后都没有找到就会抛出异常
提示:可以调用内建函数locals()和globals()来分别查看局部作用域和全局作用域的名字,查看的结果都是字典格式。在全局作用域查看到的locals()的结果等于globals()
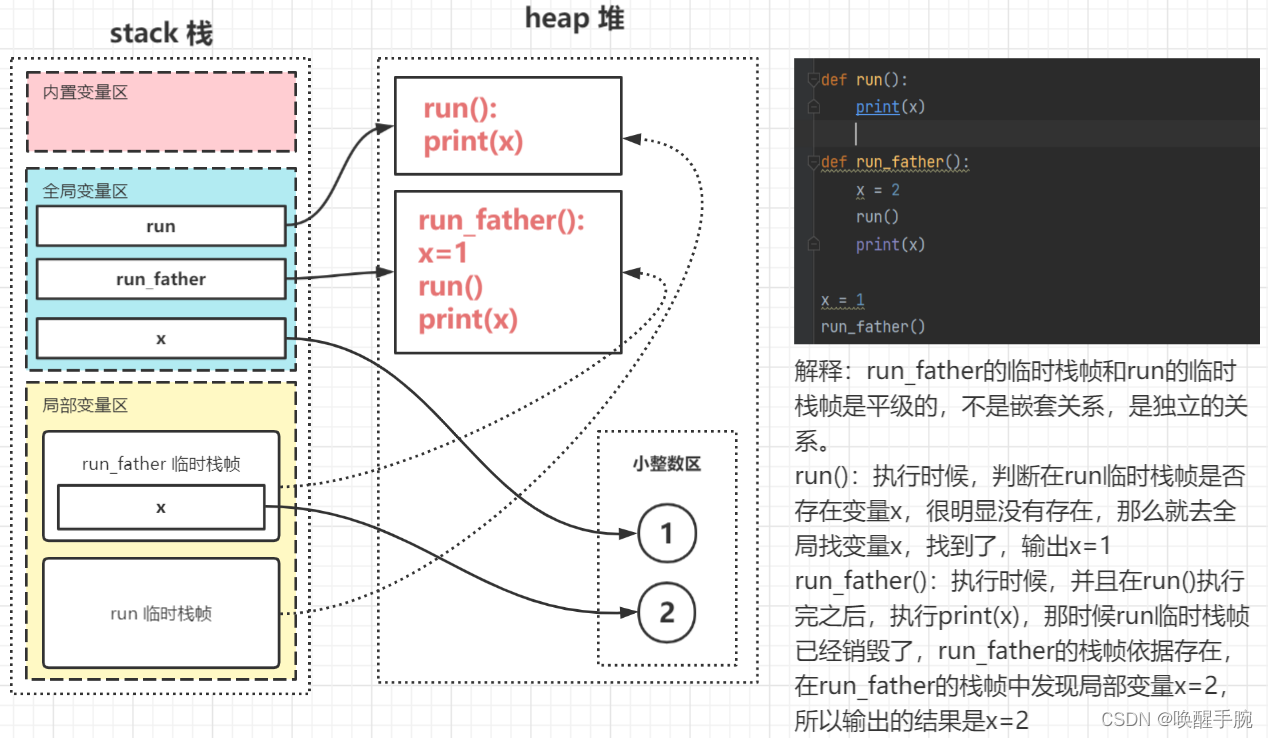
def run():print(x) # 1def run_father():x = 2run()print(x) # 2x = 1
run_father()
解释:run_father的临时栈帧和run的临时栈帧是平级的,不是嵌套关系,是独立的关系。
run():执行时候,判断在run临时栈帧是否存在变量x,很明显没有存在,那么就去全局找变量x,找到了,输出x=1
run_father():执行时候,并且在run()执行完之后,执行print(x),那时候run临时栈帧已经销毁了,run_father的栈帧依据存在,在run_father的栈帧中发现局部变量x=2,所以输出的结果是x=2
对于以上代码的图解:
x = 1
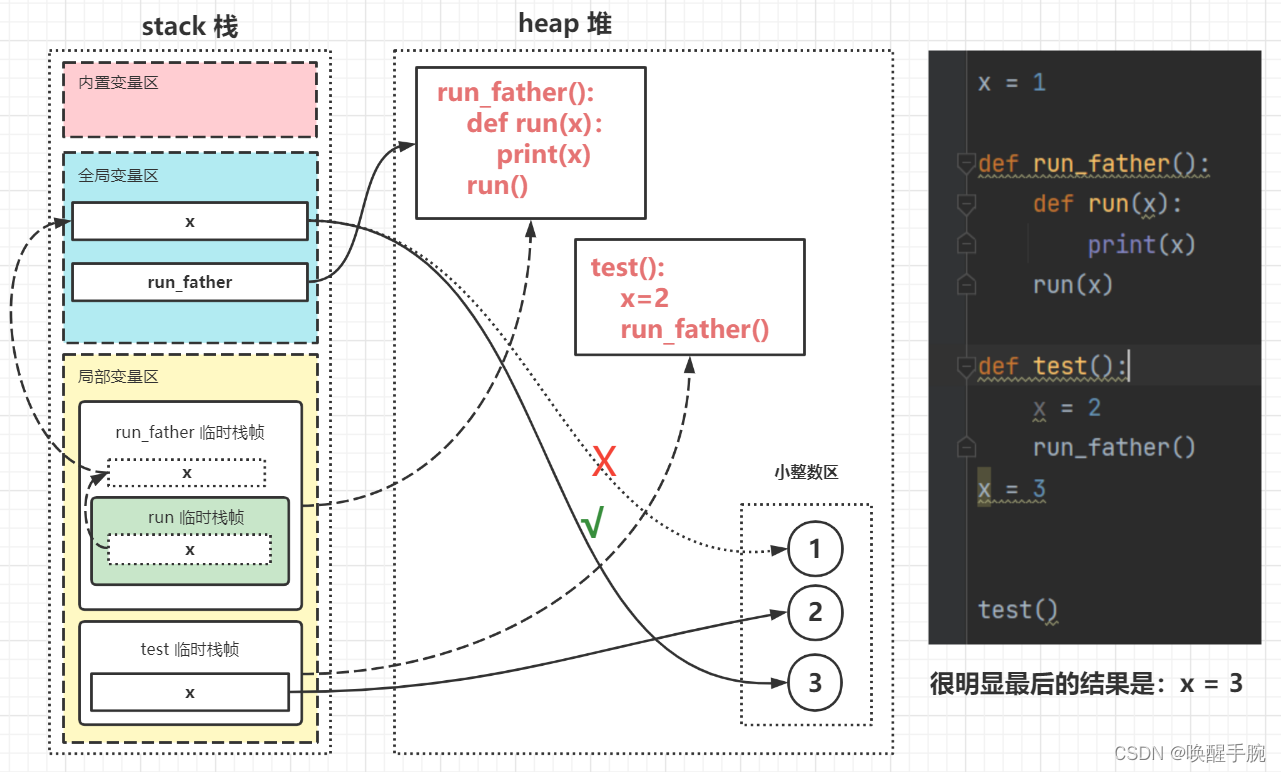
def run_father():def run(x):print(x)run(x)def test():x = 2run_father()x = 3
test()
注意点:名称空间的 " 嵌套 " 关系是以函数定义阶段为准,与调用位置无关。
对于以上代码的图解:
03、模块化的介绍
模块是一些列功能的集合体,分为三大类:1. 内置模块、2. 第三方模块、3. 自定义模块
模块分为4种形式:
- 使用python编写的.py文件
- 已被编译为共享库或DLL的C或C++扩展
- 把一系列模块组织到一起的文件夹(注 :文件夹下有一个__init__.py文件,该模块也称作“包”)
- 使用C编写并链接到python解释器的内置模块
博客引用地址:链接:https://zhuanlan.zhihu.com/p/109127048
要想在另外一个py文件中引用foo.py中的功能,需要使用import foo,首次导入模块会做三件事:
1、执行源文件代码
2、产生一个新的名称空间用于存放源文件执行过程中产生的名字
3、在当前执行文件所在的名称空间中得到一个名字foo,该名字指向新创建的模块名称空间,若要引用模块名称空间中的名字,需要加上该前缀,如下所示:
import foo
# 导入模块foo
a = foo.x
# 引用模块foo中变量x的值赋值给当前名称空间中的名字a
foo.get()
# 调用模块foo的get函数
foo.change()
# 调用模块foo中的change函数
obj = foo.Foo()
# 使用模块foo的类Foo来实例化,进一步可以执行obj.func()
加上foo.作为前缀就相当于指名道姓地说明要引用foo名称空间中的名字,所以肯定不会与当前执行文件所在名称空间中的名字相冲突,并且若当前执行文件的名称空间中存在x,执行foo.get()或foo.change()操作的都是源文件中的全局变量x。
需要强调一点是,第一次导入模块已经将其加载到内存空间了,之后的重复导入会直接引用内存中已存在的模块,不会重复执行文件,通过import sys,打印sys.modules的值可以看到内存中已经加载的模块名。
1、在Python中模块也属于第一类对象,可以进行赋值、以数据形式传递以及作为容器类型的元素等操作。
2、模块名应该遵循小写形式,标准库从python2过渡到python3做出了很多这类调整,比如ConfigParser、Queue、SocketServer全更新为纯小写形式。
导入的模块顺序介绍
我们导入的模块中可能包含有python内置的模块、第三方的模块、自定义的模块,为了便于明显地区分它们,我们通常在文件的开头导入模块,并且分类导入,一类模块的导入与另外一类的导入用空行隔开,不同类别的导入顺序如下:
# 1. python内置模块
# 2. 第三方模块
# 3. 程序员自定义模块
当然,我们也可以在函数内导入模块,对比在文件开头导入模块属于全局作用域,在函数内导入的模块则属于局部的作用域。
from-import 语句
from-import 语句from…import…与import语句基本一致,唯一不同的是:使用import foo导入模块后,引用模块中的名字都需要加上foo.作为前缀,而使用from foo import x,get,change,Foo,则可以在当前执行文件中直接引用模块foo中的名字,如下:
from foo import x,get,change # 将模块foo中的x和get导入到当前名称空间
a = x # 直接使用模块foo中的x赋值给a
get() # 直接执行foo中的get函数
change() # 即便是当前有重名的x,修改的仍然是源文件中的x
无需加前缀的好处是使得我们的代码更加简洁,坏处则是容易与当前名称空间中的名字冲突,如果当前名称空间存在相同的名字,则后定义的名字会覆盖之前定义的名字。
另外from语句支持from foo import 语法,代表将foo中所有的名字都导入到当前位置
from foo import *
#把foo中所有的名字都导入到当前执行文件的名称空间中,在当前位置直接可以使用这些名字
如果我们需要引用模块中的名字过多的话,可以采用上述的导入形式来达到节省代码量的效果。
但是需要强调的一点是:只能在模块最顶层使用的方式导入,在函数内则非法,并且的方式会带来一种副作用,即我们无法搞清楚究竟从源文件中导入了哪些名字到当前位置,这极有可能与当前位置的名字产生冲突。
模块的编写者可以在自己的文件中定义__all__变量用来控制*代表的意思
#foo.py
__all__ = ['x','get']
# 该列表中所有的元素必须是字符串类型,每个元素对应foo.py中的一个名字x = 1
def get():print(x)
def change():global xx = 0
class Foo:def func(self):print('from the func')
这样我们在另外一个文件中使用*导入时,就只能导入__all__定义的名字了
我们还可以在当前位置为导入的模块起一个别名
import foo as f
# 为导入的模块foo在当前位置起别名f,以后再使用时就用这个别名f
循环导入问题指的是在一个模块加载/导入的过程中导入另外一个模块,而在另外一个模块中又返回来导入第一个模块中的名字,由于第一个模块尚未加载完毕,所以引用失败、抛出异常,究其根源就是在python中,同一个模块只会在第一次导入时执行其内部代码,再次导入该模块时,即便是该模块尚未完全加载完毕也不会去重复执行内部代码。
搜索模块的路径与优先级
模块其实分为四个通用类别,分别是:
1、使用纯Python代码编写的py文件
2、包含一系列模块的包
3、使用C编写并链接到Python解释器中的内置模块
4、使用C或C++编译的扩展模块
导入一个模块时,如果该模块已加载到内存中,则直接引用,否则会优先查找内置模块,然后按照从左到右的顺序依次检索sys.path中定义的路径,直到找模块对应的文件为止,否则抛出异常。sys.path也被称为模块的搜索路径,它是一个列表类型:
import sysfor item in sys.path:print(item)"""
C:\Users\16204\AppData\Local\Programs\Python\Python39\python.exe C:/Users/16204/PycharmProjects/pythonProject/file_test/helloworld/foo.py
C:\Users\16204\PycharmProjects\pythonProject\file_test\helloworld
C:\Users\16204\PycharmProjects\pythonProject
F:\Python-Charm\PyCharm 2021.3\plugins\python\helpers\pycharm_display
C:\Users\16204\AppData\Local\Programs\Python\Python39\python39.zip
C:\Users\16204\AppData\Local\Programs\Python\Python39\DLLs
C:\Users\16204\AppData\Local\Programs\Python\Python39\lib
C:\Users\16204\AppData\Local\Programs\Python\Python39
C:\Users\16204\AppData\Local\Programs\Python\Python39\lib\site-packages
C:\Users\16204\AppData\Local\Programs\Python\Python39\lib\site-packages\win32
C:\Users\16204\AppData\Local\Programs\Python\Python39\lib\site-packages\win32\lib
C:\Users\16204\AppData\Local\Programs\Python\Python39\lib\site-packages\Pythonwin
F:\Python-Charm\PyCharm 2021.3\plugins\python\helpers\pycharm_matplotlib_backend
"""
列表中的每个元素其实都可以当作一个目录来看:在列表中会发现有.zip或.egg结尾的文件,二者是不同形式的压缩文件,事实上Python确实支持从一个压缩文件中导入模块,我们也只需要把它们都当成目录去看即可。
sys.path中的第一个路径:代表执行文件所在的路径
所以在被导入模块与执行文件在同一目录下时肯定是可以正常导入的,而针对被导入的模块与执行文件在不同路径下的情况,为了确保模块对应的源文件仍可以被找到,需要将源文件foo.py所在的路径添加到sys.path中。
假设foo.py所在的路径:C:/Users/16204/PycharmProjects/pythonProject/file_test/helloworld/foo.py
import syssys.path.append(r'C:/Users/16204/PycharmProjects/pythonProject/file_test/helloworld/')
# 也可以使用sys.path.insert(……)import foo
# 无论foo.py在何处,我们都可以导入它了
区分py文件的两种用途
Python文件有两种用途,一种被当主程序 / 脚本执行,另一种被当模块导入,为了区别同一个文件的不同用途,每个py文件都内置了__name__变量,该变量在py文件被当做脚本执行时赋值为“__main__”,在py文件被当做模块导入时赋值为模块名。
作为模块foo.py的开发者,可以在文件末尾基于__name__在不同应用场景下值的不同来控制文件执行不同的逻辑。
if __name__ == '__main__':foo.py被当做脚本执行时运行的代码
else:foo.py被当做模块导入时运行的代码
通常我们会在if的子代码块中编写针对模块功能的测试代码,这样foo.py在被当做脚本运行时,就会执行测试代码,而被当做模块导入时则不用执行测试代码。
编写规范的模块
我们在编写py文件时,需要时刻提醒自己,该文件既是给自己用的,也有可能会被其他人使用,因而代码的可读性与易维护性显得十分重要,为此我们在编写一个模块时最好按照统一的规范去编写,如下:
#!/usr/bin/env python #通常只在类unix环境有效,作用是可以使用脚本名来执行,而无需直接调用解释器。"The module is used to..." # 模块的文档描述import sys # 导入模块x = 1 # 定义全局变量,如果非必须,则最好使用局部变量,这样可以提高代码的易维护性,并且可以节省内存提高性能class Foo: # 定义类,并写好类的注释'Class Foo is used to...'passdef test(): # 定义函数,并写好函数的注释'Function test is used to…'passif __name__ == '__main__': # 主程序test() # 在被当做脚本执行时,执行此处的代码
04、pypi仓库上传介绍
上传模块到Pypi仓库介绍:
首先就是编写我们要上传库的核心代码,这边举例如下:
import json
import timeimport requests
import win32com.clientdef trans(words):"""Parameters pass into a string, translation, support Chinese and English translation."""API_URL = "https://fanyi.youdao.com/translate?&doctype=json&type=AUTO&i={}"api_res_data = requests.get(API_URL.format(words)).textreturn json.loads(api_res_data)["translateResult"][0][0]["tgt"]def speak(words):"""Enter the string as a parameter, and read aloud, with no return value."""SOUND = win32com.client.Dispatch("SAPI.SpVoice")SOUND.Speak(words)def shows(words):"""Enter the string as a parameter, show the result in console with colorful font."""API_URL = "https://fanyi.youdao.com/translate?&doctype=json&type=AUTO&i={}"api_res_data = requests.get(API_URL.format(words)).textresult = json.loads(api_res_data)["translateResult"][0][0]["tgt"]print("\033[1;34m{} Made From Wristwaking\033[0m\n".format(format(time.strftime("%Y-%m-%d %H:%M:%S"))))print("\033[1;34mRESULT : {}\033[0m".format(result))
然后整个工程的代码层级展示如下所示:
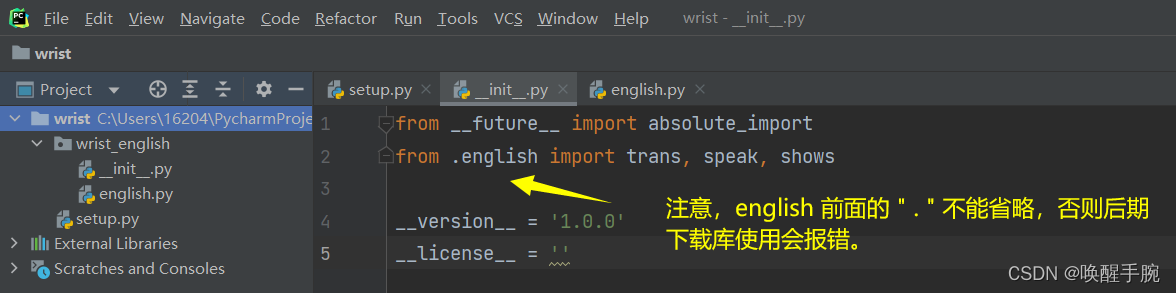
setup.py 打包脚本的编写
from setuptools import setup, find_packagessetup(name='wrist_english',version='1.0.0',keywords='english',description='Lightweight online translation tool created for learners.',license='MIT License',url='https://github.com/wristwaking/python',author='唤醒手腕',author_email='···@qq.com',packages=find_packages(),include_package_data=True,platforms='any',install_requires=['requests>=2.26.0','pypiwin32'],
)
然后使用控制台cmd窗口,cd到setup.py所在的目录,执行:python setup.py sdist,如果出现以下的报错,请更新pip的版本。

最后就是执行上传的操作,这里使用twine上传,如下:
没有就先安装:sudo pip install twine 上传包,期间会让你输入注册的用户名和密码,然后上传执行:twine upload dist/*
上传完成了会显示success,我就不演示了,然后再pypi.org上就可以看到你的包了,如下:

如果出现以下的报错,就是版本的重复,或者包名与仓库中已存在的库重名,建议修改包名或版本号进行解决报错。

最后打开pypi的官网:www.pypi.org,就能搜索到自己的库了。
05、包的使用规范
随着模块数目的增多,把所有模块不加区分地放到一起也是极不合理的,于是Python为我们提供了一种把模块组织到一起的方法,即创建一个包。包就是一个含有__init__.py文件的文件夹,文件夹内可以组织子模块或子包,例如:
pool/ #顶级包
├── __init__.py
├── futures #子包
│ ├── __init__.py
│ ├── process.py
│ └── thread.py
└── versions.py #子模块
在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则 import 包报错
创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包的本质就是一种模式
导入包与__init__.py
包属于模块的一种,因而包以及包内的模块均是用来被导入使用的,而绝非被直接执行,首次导入包(如import pool)同样会做三件事:
1、执行包下的__init__.py文件
2、产生一个新的名称空间用于存放__init__.py执行过程中产生的名字
3、在当前执行文件所在的名称空间中得到一个名字pool,该名字指向__init__.py的名称空间,例如http://pool.xxx和pool.yyy中的xxx和yyy都是来自于pool下的__init__.py,也就是说导入包时并不会导入包下所有的子模块与子包。
import poolpool.versions.check() # 抛出异常AttributeError
pool.futures.process.ProcessPoolExecutor(3) # 抛出异常AttributeError
pool.versions.check()要求pool下有名字versions,进而pool.versions下有名字check。pool.versions下已经有名字check了,所以问题出在pool下没有名字versions,这就需要在pool下的__init__.py中导入模块versions
1、关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如 import 顶级包,子包,子模块,但都必须遵循这个原则。但对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
2、包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
3、import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
绝对导入与相对导入
针对包内的模块之间互相导入,导入的方式有两种:
1、绝对导入:以顶级包为起始
#pool下的__init__.py
from pool import versions
2、相对导入:.代表当前文件所在的目录,..代表当前目录的上一级目录,依此类推
#pool下的__init__.py
from . import versions
同理,针对pool.futures.process.ProcessPoolExecutor(3),则需要
# 操作pool下的__init__.py,保证pool.futures
from . import futures # 或from pool import futures# 操作futrues下的__init__.py,保证pool.futures.process
from . import process # 或from pool.futures import process
import也能使用绝对导入,导入过程中同样会依次执行包下的
__init__.py,只是基于import导入的结果,使用时必须加上该前缀
相对导入只能用from module import symbol的形式,import …versions语法是不对的,且symbol只能是一个明确的名字
from pool import futures.process #语法错误
from pool.futures import process #语法正确
针对包内部模块之间的相互导入推荐使用相对导入,需要特别强调:
1、相对导入只能在包内部使用,用相对导入不同目录下的模块是非法的
2、无论是import还是from-import,但凡是在导入时带点的,点的左边必须是包,否则语法错误
from 包 import *
在使用包时同样支持from pool.futures import * ,毫无疑问*代表的是futures下__init__.py中所有的名字,通用是用变量__all__来控制*代表的意思
#futures下的__init__.py
__all__=['process','thread']
最后说明一点,包内部的目录结构通常是包的开发者为了方便自己管理和维护代码而创建的,这种目录结构对包的使用者往往是无用的,此时通过操作__init__.py可以“隐藏”包内部的目录结构,降低使用难度,比如想要让使用者直接使用
import poolpool.check()
pool.ProcessPoolExecutor(3)
pool.ThreadPoolExecutor(3)
需要操作pool下的__init__.py
from .versions import check
from .futures.process import ProcessPoolExecutor
from .futures.thread import ThreadPoolExecutor
06、双下滑线变量介绍
♥ ♥ ♥ __file__:查看模块的源文件路径
仍以前面章节创建的 my_package 包为例,下面代码尝试使用 __file__ 属性获取该包的存储路径:
import my_package
print(my_package.__file__)
程序输出结果为:
C:\Users\mengma\Desktop\my_package\__init__.py
注意,因为当引入 my_package 包时,其实际上执行的是 __init__.py 文件,因此这里查看 my_package 包的存储路径,输出的__init__.py 文件的存储路径。再以 string 模块为例:
import string
print(string.__file__)
程序输出结果为:
D:\python3.6\lib\string.py
由此,通过调用 __file__ 属性输出的绝对路径,我们可以很轻易地找到该模块(或包)的源文件。
注意,并不是所有模块都提供
__file__属性,因为并不是所有模块的实现都采用 Python 语言,有些模块采用的是其它编程语言(如 C语言)。
import time
import builtinsprint(time.__file__)
print(builtins.__file__)
Traceback (most recent call last):File "C:\Users\16204\PycharmProjects\pythonProject\file_test\test.py", line 7, in <module>print(builtins.__file__)
AttributeError: module 'builtins' has no attribute '__file__'
♥ ♥ ♥ __all__:变量用法
事实上,当我们向文件导入某个模块时,导入的是该模块中那些名称不以下划线(单下划线“_”或者双下划线“__”)开头的变量、函数和类。因此,如果我们不想模块文件中的某个成员被引入到其它文件中使用,可以在其名称前添加下划线。
我们通常会在Python的源码或者一些代码中会看到__all__=[<string>],比如,__all__=['main']。这个到底有啥用呢。简单地来说,就是限制from * import *中import的包名。
__all__ = ['bar', 'baz']waz = 5
bar = 10
def baz(): return 'baz'
导入实现如下:
from foo import *print bar
print baz#The following will trigger an exception, as "waz" is not exported by the module
#下面的代码就会抛出异常,因为 "waz"并没有从模块中导出,因为 __all__ 没有定义
print waz
如果把 foo.py 中__all__给注释掉,那么上面的代码执行起来就不会有问题, import * 默认的行为是从给定的命名空间导出所有的符号(当然下划线开头的私有变量除外)。
需要注意的是
__all__只影响到了from <module> import *这种导入方式,对于from <module> import <member>导入方式并没有影响,仍然可以从外部导入。
♥ ♥ ♥ __init__.py 作用详解
__init__.py 文件的作用是将文件夹变为一个Python模块,Python 中的每个模块的包中,都有__init__.py 文件。
通常__init__.py 文件为空,但是我们还可以为它增加其他的功能。我们在导入一个包时,实际上是导入了它的__init__.py文件。这样我们可以在__init__.py文件中批量导入我们所需要的模块,而不再需要一个一个的导入。
# package
# __init__.py
import re
import urllib
import sys
import os# test.py
import package
print(package.re, package.urllib, package.sys, package.os)
可以了解到,__init__.py主要控制包的导入行为。要想清楚理解__init__.py文件的作用,还需要详细了解一下import语句引用机制:
可以被import语句导入的对象是以下类型:
- 模块文件(.py文件)
- C 或 C++扩展(已编译为共享库或DLL文件)
- 包(包含多个模块)
- 内建模块(使用C编写并已链接到Python解释器中)
♥ ♥ ♥ __annotations__:参数提示
Annotations 为变量、类属性、函数的形参或返回值指定预期的类型。
局部变量的标注在运行时不可访问,但全局变量、类属性和函数的标注会分别存放模块、类和函数的 __annotations__ 特殊属性中。
它的用途虽然不是语法级别的硬性要求,但是顾名思义,它可做为函数额外的注释来用。
函数接受并返回一个字符串,注释像下面这样:def greeting(name: str) -> str:return 'Hello ' + name
在函数 greeting 中,参数 name 预期是 str 类型,并且返回 str 类型。子类型允许作为参数。
注释的一般规则是参数名后跟一个冒号(:),然后再跟一个expression,这个expression可以是任何形式。
07、序列化与反序列化
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
import json
x="[null,true,false,1]"
print(eval(x))
# 报错,无法解析null类型,而json就可以
print(json.loads(x))
为什么要序列化?
1:持久保存状态
需知一个软件/程序的执行就在处理一系列状态的变化,在编程语言中,'状态’会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台 / 语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
只有两种格式方便网络传输:1、字符流数据 2、字节流数据
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。

JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
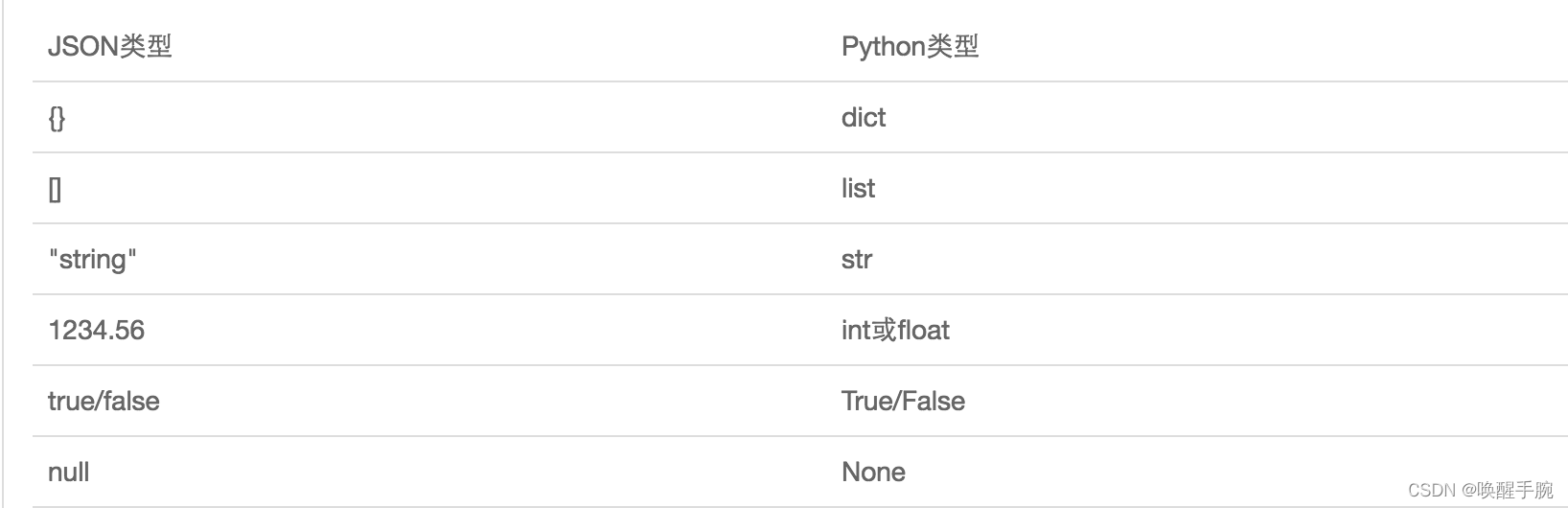
代码测试介绍:序列化、反序列化
import jsondic = {'name': '唤醒手腕', 'age': 21, 'sex': 'male'}
print(type(dic)) # <class 'dict'>j = json.dumps(dic)
print(type(j)) # <class 'str'>f = open('序列化对象', 'w')
f.write(j) # 等价于json.dump(dic,f)
f.close()# 反序列化
import jsonf = open('序列化对象')
data = json.loads(f.read()) # 等价于data=json.load(f)
json使用的注意点:生成的数据含单引号不符合json格式规范
import jsondct = "{'1':111}"
# json 不认单引号
dct = str({"1": 111})
# 报错, 因为生成的数据还是单引号 : {'one': 1}dct = '{"1":"111"}'
print(json.loads(dct))# conclusion:
# 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来, 不一定非要dumps的数据才能loads
json 只能读取一个文档对象
with open(json_path, 'r') as f:json_data = json.load(f)
就会报错:抛出异常JSONDecodeError。表示数据错误,数据太多,第2行第一列
因为 json 只能读取一个文档对象,有两个解决办法:
1、单行读取文件,一次读取一行文件。
2、保存数据源的时候,格式写为一个对象。
json.decoder.JSONDecodeError: Extra data: line 2 column 1 (char 17)
在python解释器2.7与3.6之后都可以json.loads(bytes类型),但唯独3.5不可以
pickle
pickle提供了一个简单的持久化功能。可以将对象以文件的形式存放在磁盘上。pickle模块只能在Python中使用,python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化。
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。

pickle.dump(obj, file[, protocol])
序列化对象,并将结果数据流写入到文件对象中。参数protocol是序列化模式,默认值为0,表示以文本的形式序列化。protocol的值还可以是 1 或 2 ,表示以二进制的形式序列化。
pickle.load(file)
反序列化对象。将文件中的数据解析为一个Python对象。
import pickleclass Person:def __init__(self, name, age):self.name = nameself.age = agedef show(self):printself.name + "_" + str(self.age)person_obj = Person("JGood", 20)
person_obj.show()
f = open(r'd:/person_obj.txt', 'w')
pickle.dump(person_obj, f, 0)
f.close()
# del Person
f = open(r'd:/person_obj.txt', 'r')
person_obj_load = pickle.load(f)
f.close()
person_obj_load.show()
如果不注释掉del Person的话,那么会报错:意思就是当前模块找不到类的定义了。
如果希望透明地存储 Python 对象,而不丢失其身份和类型等信息,则需要某种形式的对象序列化:它是一个将任意复杂的对象转成对象的文本或二进制表示的过程。同样,必须能够将对象经过序列化后的形式恢复到原有的对象。在 Python 中,这种序列化过程称为 pickle,可以将对象 pickle 成字符串、磁盘上的文件或者任何类似于文件的对象,也可以将这些字符串、文件或任何类似于文件的对象 unpickle 成原来的对象。
08、hash算法的介绍
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
哈希表是根据设定的哈希函数H(key)和处理冲突方法将一组关键字映射到一个有限的地址区间上,并以关键字在地址区间中的象作为记录在表中的存储位置,这种表称为哈希表或散列,所得存储位置称为哈希地址或散列地址。作为线性数据结构与表格和队列等相比,哈希表无疑是查找速度比较快的一种。
通过将单向数学函数(有时称为“哈希算法”)应用到任意数量的数据所得到的固定大小的结果。如果输入数据中有变化,则哈希也会发生变化。哈希可用于许多操作,包括身份验证和数字签名。也称为“消息摘要”。
简单解释:哈希(Hash)算法,即散列函数。它是一种单向密码体制,即它是一个从明文到密文的不可逆的映射,只有加密过程,没有解密过程。同时,哈希函数可以将任意长度的输入经过变化以后得到固定长度的输出。哈希函数的这种单向特征和输出数据长度固定的特征使得它可以生成消息或者数据。
常用hash算法的介绍:
(1)MD4
MD4(RFC 1320)是 MIT 的Ronald L. Rivest在 1990 年设计的,MD 是 Message Digest(消息摘要) 的缩写。它适用在32位字长的处理器上用高速软件实现——它是基于 32位操作数的位操作来实现的。
(2)MD5
MD5(RFC 1321)是 Rivest 于1991年对MD4的改进版本。它对输入仍以512位分组,其输出是4个32位字的级联,与 MD4 相同。MD5比MD4来得复杂,并且速度较之要慢一点,但更安全,在抗分析和抗差分方面表现更好。
(3)SHA-1及其他
SHA1是由NIST NSA设计为同DSA一起使用的,它对长度小于264的输入,产生长度为160bit的散列值,因此抗穷举(brute-force)性更好。SHA-1 设计时基于和MD4相同原理,并且模仿了该算法。
常见hash算法的原理
散列表,它是基于快速存取的角度设计的,也是一种典型的“空间换时间”的做法。顾名思义,该数据结构可以理解为一个线性表,但是其中的元素不是紧密排列的,而是可能存在空隙。
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
比如我们存储70个元素,但我们可能为这70个元素申请了100个元素的空间。70/100=0.7,这个数字称为负载因子。我们之所以这样做,也是为了“快速存取”的目的。我们基于一种结果尽可能随机平均分布的固定函数H为每个元素安排存储位置,这样就可以避免遍历性质的线性搜索,以达到快速存取。但是由于此随机性,也必然导致一个问题就是冲突。所谓冲突,即两个元素通过散列函数H得到的地址相同,那么这两个元素称为“同义词”。这类似于70个人去一个有100个椅子的饭店吃饭。散列函数的计算结果是一个存储单位地址,每个存储单位称为“桶”。设一个散列表有m个桶,则散列函数的值域应为[0,m-1]。
常见的几种Hash函数:直接定址法、数字分析法、平方取中法、折叠法、随机数法、除留余数法
解决冲突的办法:
(1)线性探查法:冲突后,线性向前试探,找到最近的一个空位置。缺点是会出现堆积现象。存取时,可能不是同义词的词也位于探查序列,影响效率。
(2)双散列函数法:在位置d冲突后,再次使用另一个散列函数产生一个与散列表桶容量m互质的数c,依次试探(d+n*c)%m,使探查序列跳跃式分布。
hash算法的用途
(1) 文件校验
我们比较熟悉的校验算法有奇偶校验和CRC校验,这2种校验并没有抗数据篡改的能力,它们一定程度上能检测并纠正数据传输中的信道误码,但却不能防止对数据的恶意破坏。
MD5 Hash算法的“数字指纹”特性,使它成为目前应用最广泛的一种文件完整性校验和(Checksum)算法,不少Unix系统有提供计算md5 checksum的命令。
(2) 数字签名
Hash 算法也是现代密码体系中的一个重要组成部分。由于非对称算法的运算速度较慢,所以在数字签名协议中,单向散列函数扮演了一个重要的角色。 对 Hash 值,又称“数字摘要”进行数字签名,在统计上可以认为与对文件本身进行数字签名是等效的。而且这样的协议还有其他的优点。
(3) 鉴权协议
如下的鉴权协议又被称作挑战–认证模式:在传输信道是可被侦听,但不可被篡改的情况下,这是一种简单而安全的方法。
hashlib 库的使用
当前,在大部分操作系统下,hashlib模块支持md5(), sha1(), sha224(), sha256(), sha384(), sha512(), blake2b(),blake2s(),sha3_224(), sha3_256(), sha3_384(), sha3_512(), shake_128(), shake_256()等多种hash构造方法。
这些构造方法在使用上通用,返回带有同样接口的hash对象,对算法的选择,差别只在于构造方法的选择。
例如sha1()能创建一个SHA-1对象,sha256()能创建一个SHA-256对象。然后就可以使用通用的update()方法将bytes类型的数据添加到对象里,最后通过digest()或者hexdigest()方法获得当前的摘要。
hashlib.new(name[, data])
一个通用的构造方法,name是某个算法的字符串名称,data是可选的bytes类型待摘要的数据。
hash.update(arg)
# 更新hash对象。连续的调用该方法相当于连续的追加更新。例如m.update(a); m.update(b)相当于m.update(a+b)。注意,当数据规模较大的时候,Python的GIL在此时会解锁,用于提高计算速度。
# 一定要理解update()的作用,由于消息摘要是只针对当前状态产生的,所以每一次update后,再次计算hexdigest()的值都会不一样。hash.digest()
# 返回bytes格式的消息摘要hash.hexdigest()
# 与digest方法类似,不过返回的是两倍长度的字符串对象,所有的字符都是十六进制的数字。通常用于邮件传输或非二进制环境中。通常我们比较摘要时,比较的就是这个值!# hash.copy()
返回一个hash对象的拷贝
那么消息摘要有什么用呢?最常用的就是密码加密!密码加密不像数据加密,通常不需要反向解析出明文。而数据加密一般是需要反向解析的,我们无法从摘要反向解析出数据,加密是没问题了,但你让数据使用者如何获取数据?
当用户登录时,首先计算用户输入的明文口令的摘要值,然后和数据库存储的摘要值进行对比。如果两者一致,说明口令输入正确,如果不一致,口令肯定错误。这样,不但数据库不用储存明文密码,即使能访问数据库的管理员“叛变”了,盗走了整个数据库,也无法获知用户的明文口令。
那么采用诸如MD5等消息摘要存储口令是否就一定安全呢?也不一定!假设你是一个黑客,已经拿到了存储MD5口令的数据库,如何通过MD5反推用户的明文口令呢?暴力破解?费事费力!,真正的黑客不会这么干。很多用户喜欢用123456,abcdef,loveyou这些简单的口令,由于MD5、SHA1等所有摘要算法都是公开的,黑客可以事先通过这些算法计算出这些常用口令的摘要值,得到一个反推表:
08b9239f92786f609443b669d5a041c1 : 123456
960d15c50def228e8557d68945b5f7c0 : abcdef
47c0e829611b55cd05c680859adb8863 :loveyou
然后,无需暴力破解,只需要对比数据库的密码摘要,黑客就可以获得使用常用口令的用户账号。
加盐:额外给原始数据添加一点自定义的数据,使得生成的消息摘要不同于普通方式计算的摘要。
比如我下面给密码字符串“password”加上字符串“salt”,这里的“salt”字符串就是所谓的盐,其摘要值必然不等于正常摘要“password”字符串的值。当然这个“salt”具体是什么,完全可以自定义,而且不能告诉他人!千万不要以为加盐就是加个“salt”字符串。
md5 = hashlib.md5()
s = "password" + "salt"
md5.update(s.encode())
md5.hexdigest()
# 'b305cadbb3bce54f3aa59c64fec00dea'
09、class类的总结
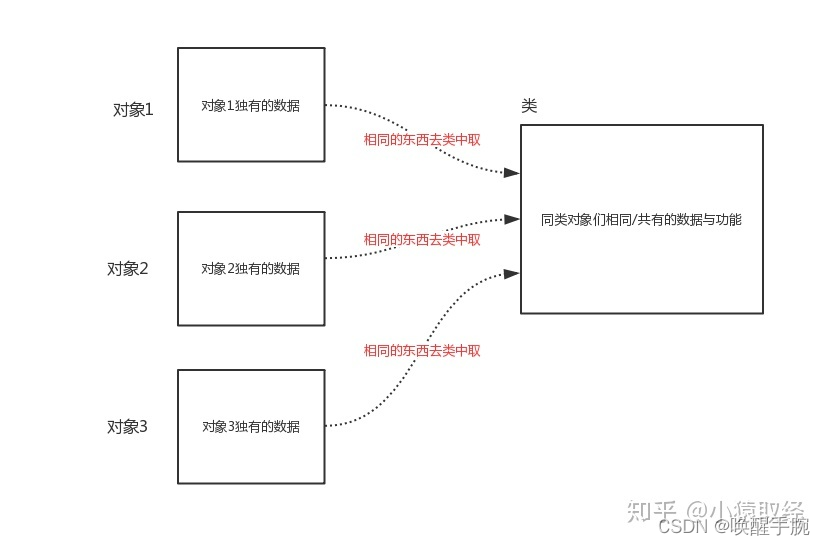
类即类别/种类,是面向对象分析和设计的基石,如果多个对象有相似的数据与功能,那么该多个对象就属于同一种类。

有了类的好处是:我们可以把同一类对象相同的数据与功能存放到类里,而无需每个对象都重复存一份,这样每个对象里只需存自己独有的数据即可,极大地节省了空间。所以,如果说对象是用来存放数据与功能的容器,那么类则是用来存放多个对象相同的数据与功能的容器。
类体最常见的是变量的定义和函数的定义,但其实类体可以包含任意Python代码,类体的代码在类定义阶段就会执行,因而会产生新的名称空间用来存放类中定义的名字,可以打印Student.__dict__来查看类这个容器内盛放的东西。
print(Student.__dict__)
{..., 'school': '清华大学', 'choose': <function Student.choose at 0x1018a2950>, ...}
属性查找顺序与绑定方法
对象的名称空间里只存放着对象独有的属性,而对象们相似的属性是存放于类中的。对象在访问属性时,会优先从对象本身的__dict__中查找,未找到,则去类的__dict__中查找
类中定义的变量是类的数据属性,是共享给所有对象用的,指向相同的内存地址。
print(id(stu1.school)) # 4301108704
print(id(stu2.school)) # 4301108704
print(id(stu3.school)) # 4301108704
10、封装与@property
面向对象编程有三大特性:封装、继承、多态,其中最重要的一个特性就是封装。封装指的就是把数据与功能都整合到一起,听起来是不是很熟悉,没错,我们之前所说的”整合“二字其实就是封装的通俗说法。
除此之外,针对封装到对象或者类中的属性,我们还可以严格控制对它们的访问,分两步实现:隐藏与开放接口

Python的Class机制采用双下划线开头的方式将属性隐藏起来(设置成私有的),但其实这仅仅只是一种变形操作,类中所有双下滑线开头的属性都会在类定义阶段、检测语法时自动变成“_类名__属性名”的形式:
- 在类外部无法直接访问双下滑线开头的属性,但知道了类名和属性名就可以拼出名字:_类名__属性,然后就可以访问了,如Foo._A__N,所以说这种操作并没有严格意义上地限制外部访问,仅仅只是一种语法意义上的变形。
- 在类内部是可以直接访问双下滑线开头的属性的,比如
self.__f1(),因为在类定义阶段类内部双下滑线开头的属性统一发生了变形。 - 变形操作只在类定义阶段发生一次,在类定义之后的赋值操作,不会变形。
开放接口的作用:
隐藏数据属性
将数据隐藏起来就限制了类外部对数据的直接操作,然后类内应该提供相应的接口来允许类外部间接地操作数据,接口之上可以附加额外的逻辑来对数据的操作进行严格地控制。
隐藏函数属性
目的的是为了隔离复杂度,例如ATM程序的取款功能,该功能有很多其他功能组成,比如插卡、身份认证、输入金额、打印小票、取钱等,而对使用者来说,只需要开发取款这个功能接口即可,其余功能我们都可以隐藏起来。
总结隐藏属性与开放接口,本质就是为了明确地区分内外,类内部可以修改封装内的东西而不影响外部调用者的代码;而类外部只需拿到一个接口,只要接口名、参数不变,则无论设计者如何改变内部实现代码,使用者均无需改变代码。这就提供一个良好的合作基础,只要接口这个基础约定不变,则代码的修改不足为虑。
@property应用
在python中定义只读属性非@property莫属,如果细心留意大部分源码,都跑不了@property的身影。而定义只读属性也很简单:以需要定义的属性为方法名(上例age属性定义为方法),其上装饰内置装饰器@property就好了。
@property真正强大的是可以限制属性的定义。往往我们定义类,希望其中的属性必须符合实际,但因为在__init__里定义的属性可以随意的修改,导致很难实现。如我想实现Person类,规定每个人(即创建的实例)的年龄必须大于18岁,正常实现的话,则必须将属性age设为只读属性,然后通过方法来赋值,代码如下:
class Person(object):def __init__(self, name, age):self.name = nameself.__age = 18@propertydef age(self):return self.__agedef set_age(self, age): #定义函数来给self.__age赋值if age < 18:print('年龄必须大于18岁')returnself.__age = age
在开头说过,@property是个描述符(decorator),实际上他本身是类,不信的话,可以将上述代码修改如下:
class Person(object):def __init__(self, name, age):self.name = nameself.__age = 18def get_age(self): #恢复用方法名来获取以及定义return self.__agedef set_age(self, age): if age < 18:print('年龄必须大于18岁')returnself.__age = agereturn self.__ageage = property(get_age, set_age) #增加property类
上述代码的运行结果和前面一致,将@property装饰的属性方法再次修改回定义方法名,然后再类的最下方,定义:属性=property(get,set,del),这个格式是固定的,通过源码可以知道原因,property部分源码如下:
class property(object):def __init__(self, fget=None, fset=None, fdel=None, doc=None):“”“Property attribute.fgetfunction to be used for getting an attribute valuefsetfunction to be used for setting an attribute valuefdelfunction to be used for del'ing an attributeclass C(object):@propertydef x(self):"I am the 'x' property."return self._x@x.setterdef x(self, value):self._x = value@x.deleterdef x(self):del self._x”“”pass def __set__(self, *args, **kwargs): # real signature unknown""" Set an attribute of instance to value. """passdef __get__(self, *args, **kwargs): # real signature unknown""" Return an attribute of instance, which is of type owner. """passdef __delete__(self, *args, **kwargs): # real signature unknown""" Delete an attribute of instance. """pass
为了不让篇幅过长,同时影响到阅读效果,这边截取了部分,可以看到代码注释里写了官方的@property用法,同时如果是用类来实现的话,必须得按__init__的参数里顺序 fget / fset / fdel 依次填入get、set、del方法,因为都是默认参数,所以都可以省略不写。
介绍下python的描述符,定义:如果一个类里定义了__set__、__get __ 、__delete __三个方法之一,同时给另一个类的属性赋值为实例,那么该类可以称之为描述符。因为描述符的使用目前就python,所以了解下就行了。
11、类的继承与派生
继承是一种创建新类的方式,在Python中,新建的类可以继承一个或多个父类,新建的类可称为子类或派生类,父类又可称为基类或超类。
通过类的内置属性__bases__可以查看类继承的所有父类。
SubClass2.__bases__
(<class '__main__.ParentClass1'>, <class '__main__.ParentClass2'>)
在Python2中有经典类与新式类之分,没有显式地继承object类的类,以及该类的子类,都是经典类,显式地继承object的类,以及该类的子类,都是新式类。而在Python3中,即使没有显式地继承object,也会默认继承该类,如下:
>>> ParentClass1.__bases__
(<class ‘object'>,)
>>> ParentClass2.__bases__
(<class 'object'>,)
因而在Python3中统一都是新式类,关于经典类与新式类的区别,我们稍后讨论
提示:object类提供了一些常用内置方法的实现,如用来在打印对象时返回字符串的内置方法
__str__
属性查找
有了继承关系,对象在查找属性时,先从对象自己的__dict__中找,如果没有则去子类中找,然后再去父类中找……
大多数面向对象语言都不支持多继承,而在Python中,一个子类是可以同时继承多个父类的,这固然可以带来一个子类可以对多个不同父类加以重用的好处,但也有可能引发著名的 Diamond problem菱形问题(或称钻石问题,有时候也被称为“死亡钻石”),菱形其实就是对下面这种继承结构的形象比喻:
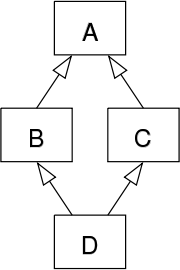
这种继承结构下导致的问题称之为菱形问题:如果A中有一个方法,B和/或C都重写了该方法,而D没有重写它,那么D继承的是哪个版本的方法:B的还是C的?如下所示:
class A(object):def test(self):print('from A')class B(A):def test(self):print('from B')class C(A):def test(self):print('from C')class D(B,C):passobj = D()
obj.test() # 结果为:from B
要想搞明白obj.test()是如何找到方法test的,需要了解python的继承实现原理
python到底是如何实现继承的呢? 对于你定义的每一个类,Python都会计算出一个方法解析顺序(MRO)列表,该MRO列表就是一个简单的所有基类的线性顺序列表,如下:
>>> D.mro() # 新式类内置了mro方法可以查看线性列表的内容,经典类没有该内置该方法
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。 而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
- 子类会先于父类被检查
- 多个父类会根据它们在列表中的顺序被检查
- 如果对下一个类存在两个合法的选择,选择第一个父类
所以obj.test()的查找顺序是,先从对象obj本身的属性里找方法test,没有找到,则参照属性查找的发起者(即obj)所处类D的MRO列表来依次检索,首先在类D中未找到,然后再B中找到方法test
深度优先和广度优先
参照下述代码,多继承结构为非菱形结构,此时,会按照先找B这一条分支,然后再找C这一条分支,最后找D这一条分支的顺序直到找到我们想要的属性:
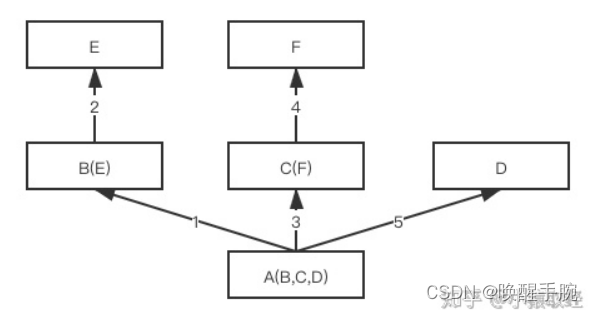
如果继承关系为菱形结构,那么经典类与新式类会有不同MRO,分别对应属性的两种查找方式:深度优先和广度优先
深度优先展示如下:
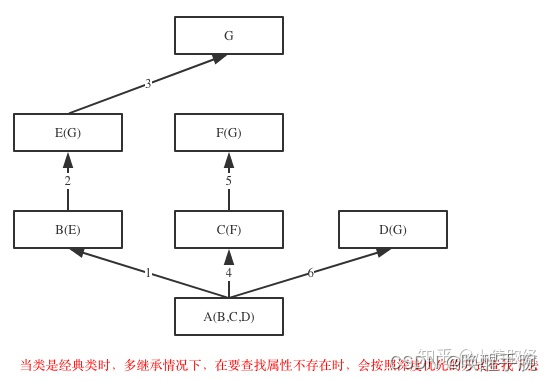
广度优先展示如下:
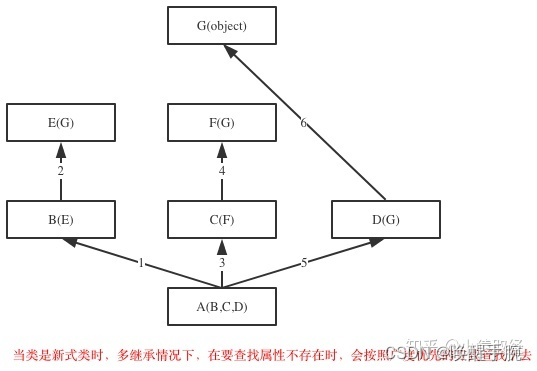
派生与方法重用
子类可以派生出自己新的属性,在进行属性查找时,子类中的属性名会优先于父类被查找,例如每个老师还有职称这一属性,我们就需要在Teacher类中定义该类自己的__init__覆盖父类的。
若想在子类派生出的方法内重用父类的功能,有两种实现方式:
方法一:“指名道姓”地调用某一个类的函数
>>> class Teacher(People):
... def __init__(self,name,sex,age,title):
... People.__init__(self,name,age,sex) #调用的是函数,因而需要传入self
... self.title=title
... def teach(self):
... print('%s is teaching' %self.name)
方法二:super()
调用super()会得到一个特殊的对象,该对象专门用来引用父类的属性,且严格按照MRO规定的顺序向后查找。
>>> class Teacher(People):
... def __init__(self,name,sex,age,title):
... super().__init__(name,age,sex) #调用的是绑定方法,自动传入self
... self.title=title
... def teach(self):
... print('%s is teaching' %self.name)
提示:在Python2中super的使用需要完整地写成super(自己的类名,self) ,而在python3中可以简写为super()。
这两种方式的区别是:方式一是跟继承没有关系的,而方式二的super()是依赖于继承的,并且即使没有直接继承关系,super()仍然会按照MRO继续往后查找。
>>> #A没有继承B
... class A:
... def test(self):
... super().test()
...
>>> class B:
... def test(self):
... print('from B')
...
>>> class C(A,B):
... pass
...
>>> C.mro() # 在代码层面A并不是B的子类,但从MRO列表来看,属性查找时,就是按照顺序C->A->B->object,B就相当于A的“父类”
[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>,<class ‘object'>]
>>> obj=C()
>>> obj.test() # 属性查找的发起者是类C的对象obj,所以中途发生的属性查找都是参照C.mro()
from B
obj.test()首先找到A下的test方法,执行super().test()会基于MRO列表(以C.mro()为准)当前所处的位置继续往后查找(),然后在B中找到了test方法并执行。
关于在子类中重用父类功能的这两种方式,使用任何一种都可以,但是在最新的代码中还是推荐使用super()
12、反射的实现原理
什么是反射?
反射的概念是由Smith在1982年首次提出的,主要是指程序可以访问、检测和修改它本身状态或行为的一种能力(自省)。这一概念的提出很快引发了计算机科学领域关于应用反射性的研究。它首先被程序语言的设计领域所采用,并在Lisp和面向对象方面取得了成绩。
反射,reflection,指的是运行时获取类型定义信息。
python面向对象中的反射:通过字符串的形式操作对象相关的属性。python中的一切事物都是对象(都可以使用反射)
可以拦截对对象属性的所有访问企图,其用途之一是在旧式类中实现特性(在旧式类中,函数property的行为可能不符合预期)。要在属性被访问时执行一段代码,必须使用一些魔法方法。
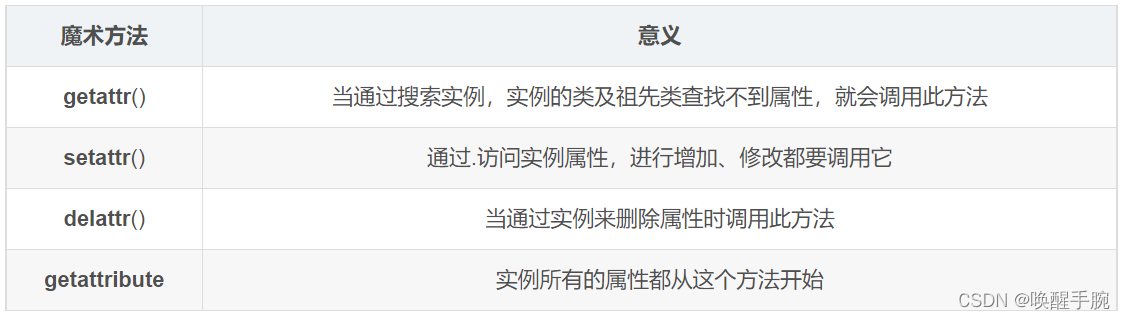
四个可以实现自省的函数
-
__getattr__(self, name):在属性被访问而对象没有这样的属性时自动调用。触发时机:获取不存在的对象成员时触发
参数:一个是接收当前对象的self,一个是获取成员名称的字符串
返回值:必须有值
作用:为访问不存在的属性设置值
注意:getattribute无论何时都会在getattr之前触发,触发了getattribute就不会在触发getattr了
-
__setattr__(self, name, value):试图给属性赋值时自动调用。触发时机:设置对象成员值的时候触发
参数:一个是当前对象的self,一个是要设置的成员名称字符串,一个是要设置的值
返回值:无过程操作
作用:接管设置操作,可以在设置前之前进行判断验证等行为
注意:在当前方法中无法使用成员,值的方式直接设置成员,否则会无限递归,必须借助object的设置方法来完成 object.setattr(参数1,参数2,参数3)
-
__deleteattr__(self, name):试图删除属性时自动调用。触发时机:删除对象成员时触发
参数:一个当前对象的self
返回值:无
作用:可以在删除成员时进行验证。
-
__getattribute__(self, name):在属性被访问时自动调用(只适用于新式类)。触发时机:使用对象成员时触发,无论成员是否存在
参数:1个接收当前对象self,一个是获取的成员的名称字符串
返回值:必须有
作用:在具有封装操作(私有化时),为程序开部分访问权限使用
一个对象能够在运行时,像照镜子一样,反射出其类型信息。简单说,在Python中,能够通过一个对象,找出其type、class、attribute或method的能力,称为反射或自省。
通过属性字典__dict__来访问对象的属性,本质上就是利用反射的能力,但是访问的方式不优雅,所以Python提供了内置的函数

实例属性会按照继承关系寻找,如果找不到,就会执行__getattr__()方法,如果没有这个方法,就会抛出AttributeError异常标识找不到属性,查找属性顺序为:
instance__dict__—>instance.class.dict—>继承的祖先类(直到object)的__dict__—>调用__getattr__()
13、元类的深入理解
当然,我们需要先理清一下思路,先看看什么是元类:
在Python当中万物皆对象,我们用class关键字定义的类本身也是一个对象,负责产生该对象的类称之为元类,元类可以简称为类的类,元类的主要目的是为了控制类的创建行为。
type是Python的一个内建元类,用来直接控制生成类,在python当中任何class定义的类其实都是type类实例化的结果。
只有继承了type类才能称之为一个元类,否则就是一个普通的自定义类,自定义元类可以控制类的产生过程,类的产生过程其实就是元类的调用过程。
一个类由三大组成部分,分别是:
1、类名class_name
2、继承关系class_bases
3、类的名称空间class_dict
方式 1:使用class关键字(python解释器转化为第二种)
方式 2:通过type关键字,依次传入以上三个参数即可。
country = 'China'
def __init__(self,name,age):self.name = nameself.age = agedef tell(self):print('%s 的年龄是:%s'%(self.name,self.age))Person = type('Person',(object,),{'country':country,'__init__':__init__,'tell':tell})print(Person.__dict__)
person = Person('唤醒手腕',22)
Person类实际上就是一个类对象,于是我们将产生类的类称之为元类,默认的元类是type
默认情况下,我们所说的元类都是指type这个元类,但是用户是可以自定义元类的,只要继承type就可以,如下所示:
class MyMetaClass(type):passcountry = 'China'
def __init__(self,name,age):self.name = nameself.age = agedef tell(self):print('%s 的年龄是:%s'%(self.name,self.age))Person = type('Person',(object,),{'country':country,'__init__':__init__,'tell':tell})print(Person.__dict__)
到现在为止,对于元类稍微了解了,为了能够顺利讲下去,我们先介绍一个__new__这个方法,之所以要讲这个,是因为我和你一样:
我开始的时候以为Python当中__init__方法就是Java当中的构造方法,其实不是这样子的,在Python当中,当我们实例化一个对象的时候,最先调用的并不是__init__方法,而是这个__new__方法。
在Python当中,简述__call__,__new__,__init__三者之间的关系
在类实例化的过程当中,哪个对象加()就寻找产生这个对象的类的__call__方法,只要是__call__方法,一定会做三件事情:
第一:调用__new__方法,构造新的对象,相当于Java当中的构造函数(对象自己的__new__)
第二:调用__init__方法,去初始化这个对象(对象自己的__init__)
第三:返回这个对象.
注意:__new__更像是其他语言当中的构造函数,必须有返回值,返回值实例化的对象,__init__只是初始化构造函数,必须没有返回值,仅仅只是初始化功能,并不能new创建对象.
也就是说,一个类在实例化的时候实际上是做了三件事情:
第一:触发元类中(造出这个类的类)的__call__方法
第二:通过__new__产生一个空对象
第三:通过__init__初始化这个对象
第四:返回这个对象
Python 中类方法、类实例方法、静态方法有何区别?
类方法:是类对象的方法,在定义时需要在上方使用“@classmethod”进行装饰,形参为cls, 表示类对象,类对象和实例对象都可调用;
类实例方法:是类实例化对象的方法,只有实例对象可以调用,形参为 self,指代对象本身;
静态方法:是一个任意函数,在其上方使用“@staticmethod”进行装饰,可以用对象直接调用,静态方法实际上跟该类没有太大关系。
class关键字创建类的流程分析
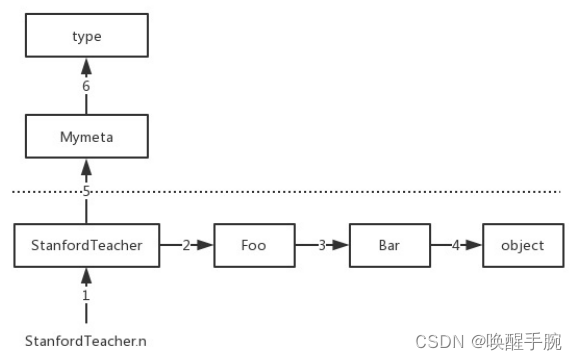
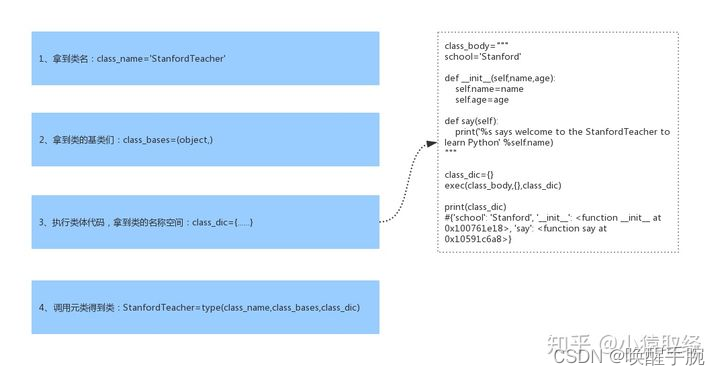
我们用class关键字定义的类本身也是一个对象,负责产生该对象的类称之为元类(元类可以简称为类的类),内置的元类为type
class关键字在帮我们创建类时,必然帮我们调用了元类StanfordTeacher=type(…),那调用type时传入的参数是什么呢?必然是类的关键组成部分,一个类有三大组成部分,分别是
1、类名class_name=‘StanfordTeacher’
2、基类们class_bases=(object,)
3、类的名称空间class_dic,类的名称空间是执行类体代码而得到的
调用type时会依次传入以上三个参数,综上,class关键字帮我们创建一个类应该细分为以下四个过程:
内置函数:exec的用法
# exec:三个参数# 参数一:包含一系列python代码的字符串# 参数二:全局作用域(字典形式),如果不指定,默认为globals()# 参数三:局部作用域(字典形式),如果不指定,默认为locals()# 可以把exec命令的执行当成是一个函数的执行,会将执行期间产生的名字存放于局部名称空间中
属性查找应该分成两层,一层是对象层(基于c3算法的MRO)的查找,另外一个层则是类层(即元类层)的查找: