您现在的位置是:主页 > news > 网站备案网站名称怎么填/品牌营销策划案例ppt
网站备案网站名称怎么填/品牌营销策划案例ppt
![]() admin2025/4/25 6:59:03【news】
admin2025/4/25 6:59:03【news】
简介网站备案网站名称怎么填,品牌营销策划案例ppt,品牌建设运营的最高境界,如何分析网站的设计WARP: Word-level Adversarial ReProgramming阅读笔记 个人学习记录,如有不足之处、建议或思想的碰撞感谢大家的指出! 研究基础回顾: 链接:预训练模型adapter的几篇论文概述 链接:parameter-efficient TL for NLP 预…
WARP: Word-level Adversarial ReProgramming阅读笔记
个人学习记录,如有不足之处、建议或思想的碰撞感谢大家的指出!
研究基础回顾:
链接:预训练模型adapter的几篇论文概述
链接:parameter-efficient TL for NLP
预训练语言研究的新宠—adapt适配器。简单的理解就是在预训练好的模型下添加新的网络层,训练新的任务时只更新新的网络层的参数,其余共享参数冻结。
论文链接:WARP: Word-level Adversarial ReProgramming
还有里面的实验数据也最好了解一下,有助于论文的理解GLUE
没有全部翻译,仅展示表达思想的部分。较为完整的部分将网盘分享。
链接:https://pan.baidu.com/s/1Sb12Y6ql_ElODzFhA2_O8g
提取码:asdf
摘要:
从训练前的语言模型中迁移学习最近成为解决许多NLP任务的主要方法。 在语言模型之上训练一个或多个特定于任务的层,这是一种将学习转移到多个任务的常见方法,可以最大限度地共享参数。在本文中,我们提出了一种基于对抗性重构的替代方法,它扩展了早期的自动提示生成工作。对抗性重构试图学习任务特定的词嵌入,指示语言模型解决指定的任务。语言模型来解决指定的任务。
1 介绍(重点内容)
基于任务重构的方法的成功表明,语言模型能够在适当的提示下解决各种自然语言处理任务。我们假设他有可能够找到这些提示。换句话说,我们可以发现当我们向输入里添加额外的tokenss时,可以更好的发展语言模型的能力相比于人工设计。
在这篇论文中,介绍了一种寻找最优提示符的新方法。称之为WARP:单词级别的对抗式重构。这个方法受到对抗式重启的启发-在一个输入图片中添加对抗式扰动来重构一个预训练的神经网络来对一项任务进行分类,而不是最初训练的任务。
2 相关研究(重点内容)
2.1 更少的可训练参数
另一种方法被称为Adapters,在transformer每一层引入新的特定任务参数。只有这些新的初始化参数被训练,并可将一般知识和特定任务的知识分离。相比较,我们的方法并没有插入特定任务知识在预训练网络的内部。相反,它聚焦于学习特定任务输入级别的提示。
2.2 任务重构
我们的方法时基于掩码语言模型,但是不像PET,我们聚焦于使用可训练样本发现最好的提示符。这消除了人工设计提示的需要,但是,通过仔细初始化提示,我们的方法也可以从关于任务的类似先验知识中受益。
2.3 对抗型重新编程
对抗型重构被采用在文本分类任务,使用的使LSTM模型【】。他们在单词空间运行,并对一个任务进行的重构模型应用于另一个任务。最新的(more recently),自动提示尝试为大型的语言模型自动去找到提示符,在没有添加任何额外模型参数的情况下。不像自动提示,我们在词嵌入空间使用基于梯度的优化方法,这给予我们的模型更大程度的自由并最终(eventually)在下游任务上有更好的表现
同一时间,【】和【】提出了一种类似的方法,并成功地将其应用于两个文本生成任务。除了不同类型的任务及我们将任务描述为一种对抗性重编程的形式外,他们的方法和我们的方法的主要区别在于,他们使用额外的参数化技巧来稳定训练。
3 WARP
设置和Elsayel(2019)类似,一些NLP特定细节的修改见图二。

论文的目标是发现最好的提示符,它使一个预训练的掩码语言模型对一个训练样本的masked token预测预期的结果。在词嵌入空间探寻提示符。换句话说,我们想要去发现提示符的参数,并嵌入化来表示(verbalizer embeddings) [没太明白这里],也就是:
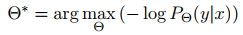
概率为:
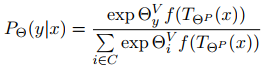
![其中 T(p(x))就是将提示符词嵌入插入预定义的位置的版块,C是类的集合,f(x)16)(https:/插入预定义的位置的版块,C是类的集合,f(x)]使掩码语言模型的输出(不需要最后一层解码器,这层仅仅是转置的字嵌入矩阵)。 与 都是同一词嵌入空间的词嵌入向量。在图二中, 模块预测 并添加 参数到词嵌入中,同时使用 与 来计算在掩码位置正负类别概率。](https://img-blog.csdnimg.cn/7e96da03c51f4b3aa95cc32faf37c291.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA552h6YaS5LqG5Y-t,size_17,color_FFFFFF,t_70,g_se,x_16)
3.1 方法
与Elsayed et al相似,我们采用随机梯度下降的方法去发现文本最好的对抗式扰动以最小化任务的训练目标。首先我们插入一个特殊的提示符tokens[P_1],[P_2], …[ P_k],这些tokens可能会出现在句子前面或者后面,取决于提示符模块,并且一个额外的[MASK]token放到输入句子中。
我们设定优化的目标为一个在掩码语言模型的头输出和类别1…C的表达符号(verbalizer tokens=class embedding?) [V_1],[V_2], …[ V_c]的交叉熵损失函数。

仅可训练的参数是词嵌入[P_1],[P_2], …[ P_k]和[V_1],[V_2], …[ V_c]。在这个案例中,我们想在多种任务中训练模型,这些是我们需要存储的惟一特定于任务的参数。语言模型的全部部分(全注意力层,前馈网络层,以及所有其他的词嵌入)仍不改变。
需要注意的是,不同于大多数的对抗攻击,我们并没有更新输入的原始tokens的词嵌入。这遵循elsayed et al的做法,当MNIST或CIFAR图像的像素保持不变时,只更新填充像素。
3.2 实施细节
。。。。。
还有实验、讨论、总结部分这里请看原论文。我是在了解了数据集之后才大概弄清楚了论文提出模型的训练方法。首先这个是有监督的语言训练模型,里面的类别输出[V_1],[V_2], …[ V_c]就是mask或者说文本类别的备选输出的词嵌入。在计算损失的时候是用[P_1],[P_2], …[ P_k]的词嵌入表示与softmax([V_1],[V_2], …[ V_c])进行交叉熵计算。训练过程中只有[P_1],[P_2], …[ P_k]、([V_1],[V_2], …[ V_c]的表示是可以被更新的。
这里面有一段对该论文的简短介绍https://zhuanlan.zhihu.com/p/407144573可以看一看








